RAG 논문을 읽고 있는데 기본적으로 알아야되는 내용들이 많다. (https://arxiv.org/pdf/2005.11401)
RAG는 검색(Retrieval)을 통해 얻은 외부 정보를 생성 모델(Generator)의 입력에 결합하여 답변을 만드는 기술적 방법론이다.
KIT (Knowledge-Intensive Tasks)
언어 모델의 파라미터 내부 지식만으로는 해결할 수 없고, 대규모 외부 문서나 DB에 접근해야만 올바른 답변을 생성할 수 있는 NLP 태스크들의 범주
(예 : 회사 내부 문서, 사내 정책, 개인정보와 같은 미리 사전에 학습할 수 없는 비공개 지식을 다루는 QA 문제)
KILT: a Benchmark for Knowledge Intensive Language Tasks (https://arxiv.org/pdf/2009.02252) 논문에서는 '어떻게 공정하게 평가할지'를 정의한 벤치마크 논문
KIT를 해결하기 위한 방법
즉, QA 문제 정의에는 3가지가 존재하는데 Closed-Book QA, Open-Book QA, Open-Domain QA (ODQA)이다.
Closed-Book QA는 질문만 주어지고 모델은 LM 파라미터 내부 지식만 사용 가능하다,
Open-Book QA는 질문과 함께 관련 문서(context)가 입력으로 주어진다.
ODQA는 질문만 주어지며 답을 찾기 위해 외부 문서 접근이 가능하고, 어떤 문서를 볼지 모델이 결정한다.
ORQA (Open-Retrieval Question Answering)

ODQA를 푸는 방법으로 DrQA, ORQA, RAG, Modern이 존재하고,
DrQA (2017)으로 ODQA의 시작 논문으로 "질문만 주고, 위키 전체에서 답을 찾아라"를 정식으로 제시한 논문이다.
Retreival에서 Sparse (TF-IDF)를 사용하는데 동의어, Paraphrase (패러프레이즈, 같은 의미 다른 표현으로 말한 문장)을 해결하지 못하면서 한계가 있었다.
ORQA는 Retreival에서 Dense를 사용한다. Dense는 의미 기반의 학습이 가능하기때문에 DrQA의 한계를 뚫었다고 볼 수 있다.
📌 Sparse Retrieval vs Dense Retrieval
Sparse Retrieval (희소 검색) 방식 : TF-IDF나 BM25 같은 정보 검색(IR) 알고리즘에 기반한 방법
질문에 포함된 키워드와 문서와 포함된 키워드가 얼마나 많이 일치(=)하는지를 기준으로 관련성을 평가 한다.
단점으로 의미는 같지만 표현이 다른 동의어 및 패러프레이즈를 처리하지 못한다는 점이 있다.
사용 예 : 정확한 키워드가 중요할 때, 코드/에러 메시지 검색, 로그 검색
Dense Retrieval (밀집 검색) : 의미를 압축해 표현한 벡터로 의미 공간(semantic embedding space)를 가지고 있다.
단어들의 의미가 비슷한 단어일수록 서로 의미 공간상에서 가까운 위치에 존재하게 학습한다.
사용 예 : 자연어 질문, 페러프레이즈 대응
Latent Retrieval for Weakly Supervised Open Domain Question Answering 논문(https://arxiv.org/pdf/1906.00300, 개방형 도메인 질의응답을 위한 잠재 검색)에 나오는 방법론이 ORQA이다.
논문 리뷰는 아니라 가볍게 어떤 개념인지만 확인하고 가려고 한다.
ORQA는 retriever와 reader로 구성되어있으며, retriever는 reader가 정답을 잘 맞히도록 돕는 방향으로 함께 학습된다.
📍 Retriever-Reader 구조
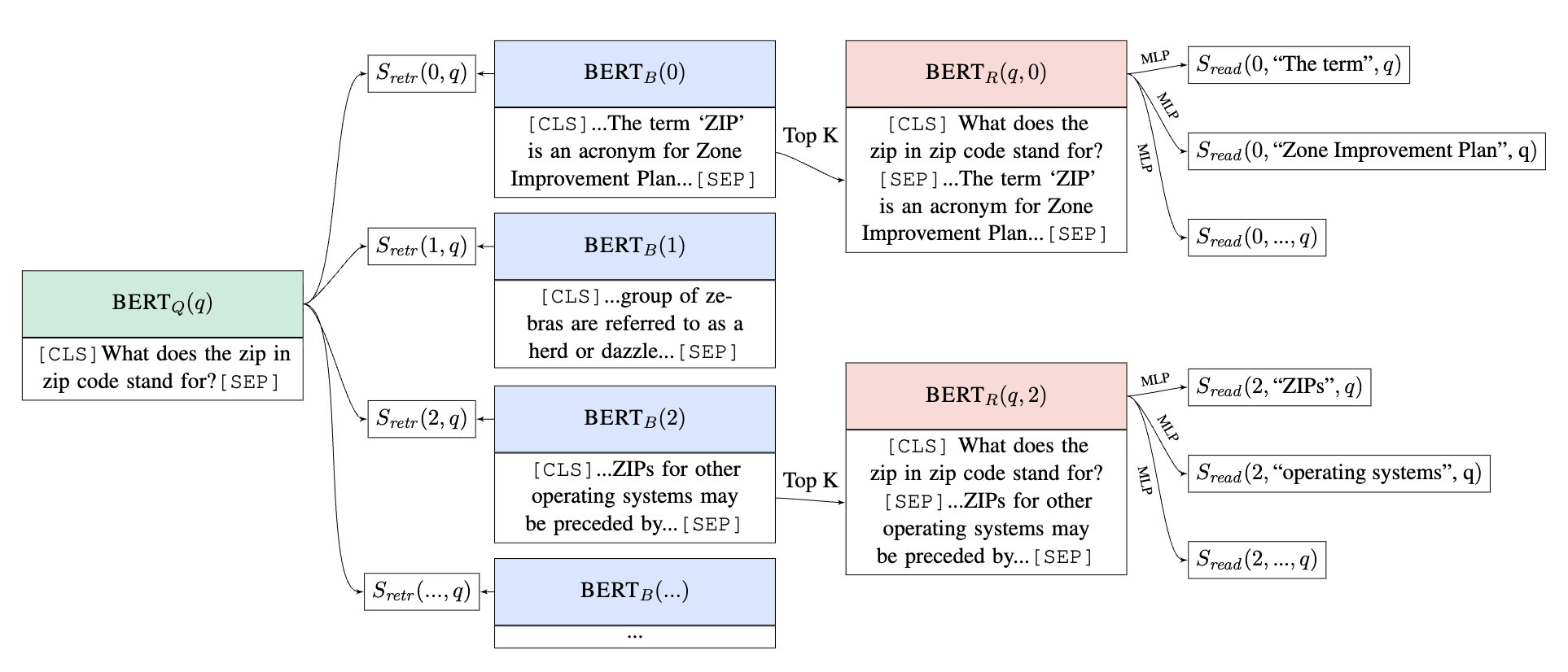
- BERT_Q(q) : 질문 인코더,
h_q : 질문 q를 BERT_Q 모델에 통과시킨 후, [CLS] 토큰에서 추출된 임베딩(embedding)에 가중치 행렬 W_q를 곱해 128차원으로 투영한 벡터 -> 질문의 의미론적 내용이 압축되어있다. - BERT_B(b) : 위키피디아와 같은 방대한 문서 집합은 수백만 개의 증거 블록(evidence blocks, 위키 문서) b로 분할한다.
h_b : 위키 벡터 b를 BERT_B 모델에 통과시킨 후, [CLS] 토큰에서 추출된 임베딩에 가중치 행렬 W_b를 곱해 128차원으로 투영한 벡터 -> 이 벡터는 증거 블록(위키 문서)의 의미론적 내용을 압축합니다. - Top K Selection : Retriever(검색기)에서 계산된 S_retr 점수를 기반으로 상위 K개 증거 블록(위키 문서)를 선택하여 Reader(독해기)에 전달한다.
$$ S_{\text{retr}}(b, q) = h_q^T h_b $$ 벡터의 내적(inner product)를 통해 계산된다.
- BERT_R : 질문과 증거 블록을 함께 이해하여, 증거 블록 내에서 질문에 대한 답변 스팬(span)을 찾는다.
답변 스팬의 시작(start) 및 끝(end) 토큰에 해당하는 표현(h_start, h_end)을 추출하고, 이를 결합하여 MLP(Multi-Layer Perceptron)에 입력하여 점수 S_read(b,s,q)를 계산한다.
위키피디아 전체로부터의 증거 검색의 어떤 위키 문서에대해 잠재 변수로 처리하며, 이를 효과적으로 학습하기 위해 비지도 학습 방법인 Inverse Cloze Task(ICT)를 사용하여 retreiver를 pre-train 한다.
evi-dence retrieval from all of Wikipedia is treated as a latent variable. 위키피디아 전체로부터의 증거 검색은 잠재 변수로 처리한다.
Inverse Cloze Task(ICT)❓
위키피디아에는 수많은 문서가 존재하기 때문에,
질문이 주어졌을 때 모든 위키 문서들을 전부 뒤지는데 계산적 한계가 있다.
ICT는 검색 단계에서 retriever가 어디부터 찾아보면 될지 방향 감각을 갖도록 해주는 사전 훈련이다.
위키는 도서관이라고 생각하면 "파스타 만드는 레시피 책 어딨어요?"라는 질문을 받았을 때 "요리 책들이 모여있는 곳은 저기 근처니 저기로 가봐!"라고 알려주는 것이 ICT가 하는 일이다.
즉, ICT가 학습하는 것은 어떤 질문이 왔을때 질문을 보고 어떤 공간에 위치하는지 알기 위해 위키 문서들의 의미적 임베딩 공간을 가지게 하는 것이다.
Cloze Task는 문맥을 기반으로 마스킹된 텍스트를 예측하는 것이 목표인데 Inverse Cloze Task는 문장이 주어졌을 때 그 문맥을 예측한다.
ICT는 Retriever가 의미 공간을 형성하는 것이 목적이고 문장과 문서 의미 연결을 할 수 있는 방법이다.
어떻게❓
ICT의 확률 계산 공식을 보면 알 수 있다.
$$ P_{\text{ICT}}(b|q) = \frac{\exp(S_{\text{retr}}(b, q))}{\sum_{b' \in \text{BATCH}} \exp(S_{\text{retr}}(b', q))} $$
- $ P_{\text{ICT}}(b|q) $ : 입력 쿼리 q가 주어졌을 때, 위키 문서 b가 올바른 문맥일 확률, ICT 학습 목표에 따라 계산되는 확률
- $ S_{\text{retr}}(b, q) $ : Retrieval Score (검색 점수), 입력 쿼리 q와 위키 문서 b 가 얼마나 관련 있는지 나타내는 점수
$ S_{\text{retr}}(b, q) = h_q^T h_b $ 질문 벡터 h_q와 위키 문서 벡터 h_b의 내적곱으로 점수가 높을수록 같은 방향이므로, b가 q에 더 관련성이 높다는 것을 의미 - $ \sum_{b' \in \text{BATCH}} \exp(S_{\text{retr}}(b', q)) $ : 모든 후보의 위키 문서 b들에대한 확률 합산 값.
해당 값을 분모로 가지고 나눠주면서 모든 후보의 위키 문서들에대한 각 위키 문서는 확률값을 지니게됨. (합이 1 - softmax) - BATCH : 현재 ICT 학습에서 고려되는 후보 위키 문서들의 집합을 의미
-> ICT로 사전 학습된 dense retriever를 사용하면, ORQA에서 입력 질문 q에 대해 위키 전체를 탐색하지 않고도 의미적으로 관련성이 높은 문서 후보 Top-K를 효율적으로 검색할 수 있다.


