RAG 수업이 끝나갈때쯤 3차 프로젝트 팀이 발표되었다. 3차 프로젝트에 주어진 시간은,,, 2일,,,😱
짧은 시간안에 RAG를 설계부터 개발까지 해야하는 상황이라 팀원들과 미리 모여서 주제선정하고 프로젝트 구성까지는 미리 잡고 시작하기로 했다.
- RAG 기반 AI Agent 개발
- Chatbot 형태로 대화 가능한 어플리케이션 구현 (화면 필수 아님, 터미널 가능)
RAG는 검색 기반으로 출처가 명확한 정보 제공을 하는 AI Agent니까 그만큼 데이터 주제가 명확해야한다고 생각했다.
법률, 요리 레시피, AI 모델들 검색해서 비교해주는 Agent 등 여러가지 의견들이 나왔고, 이야기하다보니 가장 명확한건 우리도 실제로 쓸 수 있는 Agent를 만들어 보자. 했다.
함께 지내는 수강생들도 팀원들도 수업 내용을 복습하고 정리하는 과정에서 어려움을 느끼고 있어서 SKN 21기를 위한 AI Agent를 개발하기로 결정했다.
데이터셋은 수업 강의 자료와 Python 공식 문서를 사용하기로 했고, RAG는 검색과 생성 Agent를 분리해 작업하기로 했다. 팀장을 맡게 되어 PM과 생성 AI Agent를 담당하기로 했는데 일단 가장 먼저 초기 프로젝트 구조 설계를 작업했다.
SKN21_3rd_4Team
├── data/ # RAG 학습 및 검색에 사용되는 데이터
│ └── raw/ # 원본 데이터 (강의 자료, 문서 등)
│
├── notebooks/ # 실험 및 분석용 Jupyter Notebook
├── results/ # 검색 결과, 실험 결과 저장
│
├── src/ # 핵심 소스 코드
│ ├── agent/ # Search / Analysis Agent 로직
│ ├── schema/ # 데이터 및 응답 스키마 정의
│ ├── utils/ # 공통 유틸리티 함수
│ └── ingestion.py # 데이터 수집 및 전처리 파이프라인
│
├── templates/ # Flask 렌더링 템플릿
│
├── app.py # Flask 기반 웹 애플리케이션 진입점
├── main.py # 전체 파이프라인 실행 메인 파일
├── init_setting.py # 초기 환경 및 설정 관리
│
├── intro.md # 프로젝트 소개 문서
├── README.md # 프로젝트 설명 문서
│
├── requirements.txt # Python 패키지 의존성
├── pyproject.toml # 프로젝트 설정 및 빌드 정보
│
├── unit_test.ipynb # 단위 테스트 및 기능 검증 노트북
└── utils.py # 보조 유틸리티 함수UI에 관심많은 팀원이 html로 진행하고 싶다 하여 Flask 연동 초기 구성도 잡아놓았다.
📌 LangGraph 기반 Multi Agent Workflow
시간이 많지 않기 때문에 병렬 개발이 중요하다고 생각했고, 팀원 6명이 진행하기엔 Multi Agent로 진행해야된다고 판단했다. 데이터 전처리와 VectorDB 구성까지 생각해서 검색 Agent와 생성 Agent 구분하여 LangGraph 기반으로 구성을 잡았다.
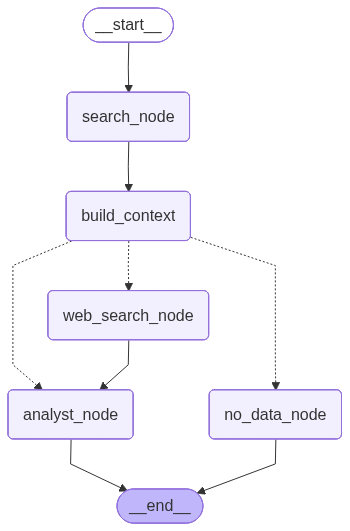
유사도 평가 점수에따라 데이터 없음으로 답변하는걸로 진행했다. "오늘 점심 뭐먹을까" 이런 질문을 하면 "관련 문서가 없습니다."라는 답변을 하도록 되어있다는 것. 검색 문서와 유사도 점수가 0.3보다 낮게 나오는걸 정성 평가로 확인하고 분기에대한 기준을 잡았다.
📌 데이터 전처리
강의자료는 Jupyter Notebook으로 되어있어서 markdown cell과 code cell로 구분되어있었다. 두개를 분리해서 전처리를 진행했고 markdown은 Header 기반으로 나눈 후 RecursiveCharacterTextSplitter를 사용해서 진행했고, code는 RecursiveCharacterTextSplitter 단독 사용해서 진행했다. 이미지의 경우엔 모두 제외하기로 해서 전처리 단계에서 제거했다.
Qdrant로 저장을 하고 팀원 모두 하나의 DB를 보기 위해 스크린샷을 해서 huggingface에 데이터셋으로 올려놓았다. 강사님 자료라 일정 기간 후에는 비공개로 해야된다.
cpython/Doc at main · python/cpython
The Python programming language. Contribute to python/cpython development by creating an account on GitHub.
github.com
Python Document는 처음에 txt 파일을 찾아서 진행했는데 전처리 단계에서 title이나 구분자 같은게 없어서 어려움이 있었다. 그때 팀원분이 rst 파일에대해서 알아오셨고 RAG는 txt 파일보다 rst (reStructuredText, 마크업 포맷) 파일이 더 좋다고 하여 rst 파일을 디비화하기로 중간에 변경했다.
살짝 아쉽게 남은건 강의 자료를 직접 하나하나 더 챙겨보면서 수업 자료 카테고리별로 분리하고 벡터화를 시키고 싶었는데 시간상 파일 하나를 단위로 잡고 가서 떨어져있는 내용 같은 경우, 불러오기 쉽지 않았다. 추가로 Qdrant의 SparseDB는 적용하지 못한것! 적용했다면 검색 Agent에서 키워드 검색이 좀더 수월했을텐데 거기까지 진행하지는 못했다.
📌 생성 Agent
생성 Agent는 생각보다 빠르게 작업이 완료 되었고, 검색 Agent에서 검색 품질이 안좋을때에대한 고민들을 하면서 LangGraph로 구성잡아놓은게 빛을 바랬다.ㅎㅎㅎ
점수가 0.3~0.5인 경우, Tavily Search를 통해서 내용을 보완해주는 역할을 추가했다. (web_search_node)

정량평가를 진행했을때, 검색 성능에비해 생성 성능이 안좋은 점수를 받았는데 생성 AI 프롬프트를 너무 검색 결과 context에 강하게 제한을 두고 여러번 강조도 해서 성능이 좀 떨어지게 나왔다.
context에대한 제한을 좀 풀고 AI를 달래주듯,,,❓ 질문이 들어온것부터 한단계 한단계 접근하도록 프롬프트를 수정하였다.
질문을 먼저 파악하고~ 강의자료와 외부자료에대한 우선순위 설정~ 불필요한건 빼줘~
최종적으론 Context Recall이 1.0에서 0.85로 떨어졌지만 Answer relenvancy가 0.68에서 0.83으로 올릴 수 있었다. 평균 점수를 더 올릴 수 있는 방법을 찾다가 강사님께 문의드렸는데 강사님이 LLM에서는 정량 평가보다는 정성 평가를 더 중요하게 볼 때가 많다고 정성평가에서 문제 없으면 그대로 진행해도 된다 하셔서 정성 평가에서도 더 좋은 성능을 보였기때문에 이대로 진행하기로 했다.

📌 검색 Agent
검색 Agent에서는 단일 VectorDB로는 검색 품질을 올리는게 어렵다하여, 하이브리드 검색을 넣기로 하였다.
의미적 유사도와 키워드 매칭, 단어 빈도 기반 중요도까지 가중치에 따라 최종 문서 점수를 평가하여 검색 문서 순위를 결정해 생성 Agent에 전달해주는 형태이다.
# 단어 하나일때 0.4 0.3 0.3
# 문장일때 0.6 0.2 0.2
hybrid_score = (
vector_score * 0.6 + # 의미적 유사도
keyword_score * 0.2 + # 정확한 키워드 매칭
bm25_score * 0.2 # 단어 빈도 기반 중요도
)Python Document 자료같은 경우, 영어가 base언어다보니까 한국어로 검색할때보다 영어로 검색할 때 검색 성능이 좋다는 것을 알고 질문을 영어로 번역해서 질문하는 로직을 추가했다. 이걸 알아차린 팀원분이 고민을 진짜 많이 했고, 아이디어가 진짜 좋다라고 생각했다. 번역하는 시간이 검색 결과를 내는데까지 시간을 delay시키지 않을까 했는데 다행히 그정도로 속도가 저하되거나 하지 않았고, 정성 평가했을때 더 효과가 좋았다.
PMI
Plus (좋았던 점)
RAG의 전체 개발을 직접 설계해보고 개발해봐서 너무 재밌었다. 이렇게 AI ChatBot이 나오는구나 싶고 직접 개발한 Agent의 정성 평가에서 안정성있게 답변을 해서 더 신기했던거 같다.
이미 찾아온 AI 시대에 얼마나 더 AI가 차지하게 될까, 또 어떤 부분들을 사람들에게 제공할 수 있을까 하는 재밌는 생각들을 해볼 수 있었다.
ChatBot 이름은 Python Mate해서 PyMate로 정하고 팀명은 강사님 강의 자료 기반이니 SH LAB으로 우리 마음대로 정했다👍
Logo캐릭터는 강사님이 소띠라서 소 캐릭터가 있다!! 컨셉 확실해서 너무 재밌었다ㅎ

Minus (아쉬웠던 점)
처음으로 전체적인 구조 잡고 RAG 개발을 진행하다보니 놓친 점들이 이제서야 보인다. PM과 개발을 동시에 진행하다보니 개발에 집중하게 되면 멀티가 안되서😅 다른 파트는 신경 써주지 못하는 시간들이 있어서 팀원들에게 미안한 점도 있다.
Impressive (인상적이었던 점)
Retriever 담당한 팀원분이 검색 성능을 높이기 위해 많은 고민한 부분들과 새벽 늦게까지 작업해오시고, 전체적인 서비스 성능을 높이기 위해 데이터 전처리 부분까지 다방면으로 애써줬다. 내가 Generator Agent 개발에 집중할때는 다른 팀원분들과 할 수있는 일들을 찾아 해주셨다. 너무 든든했고 대단하다고 생각했다.
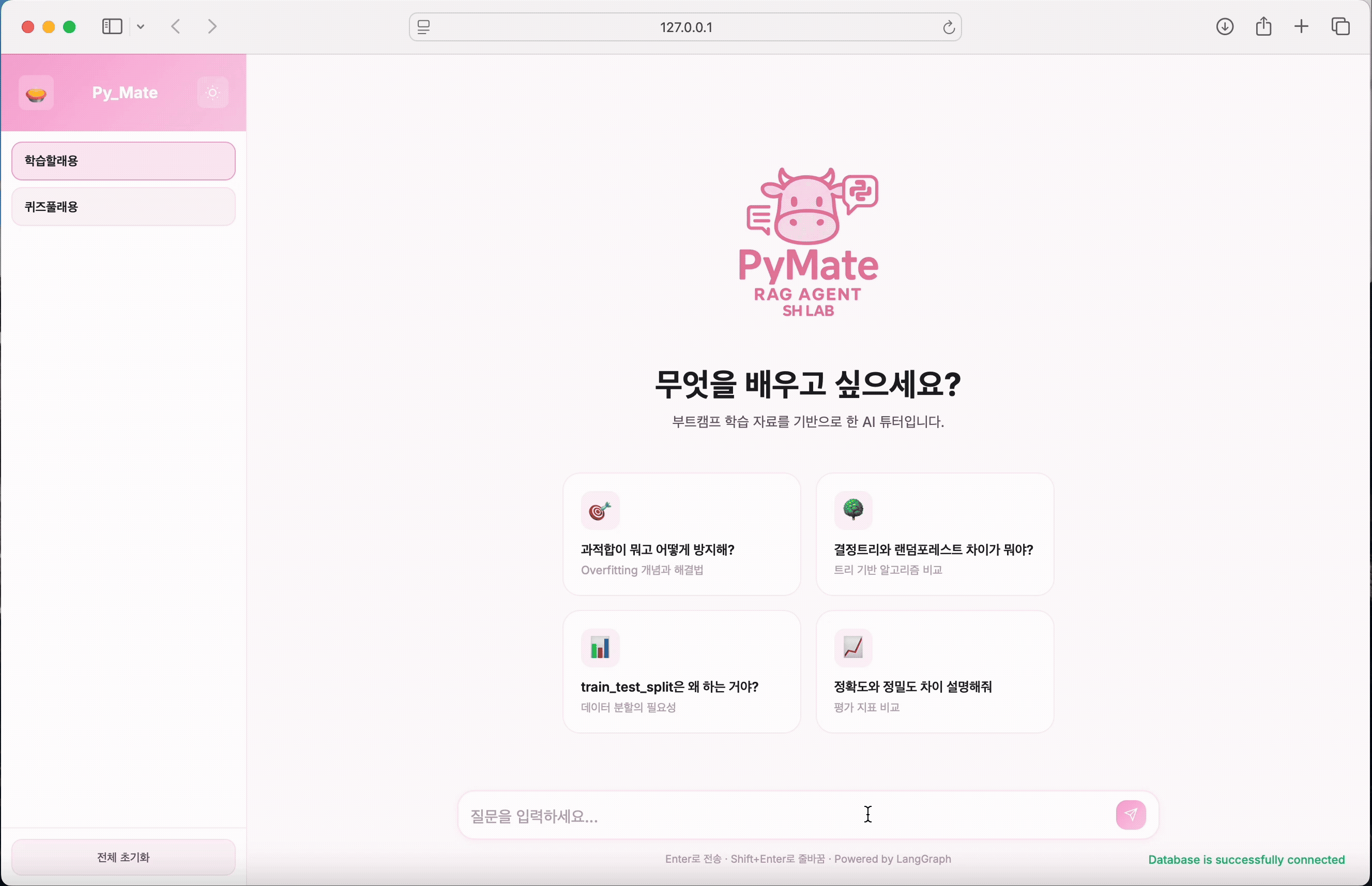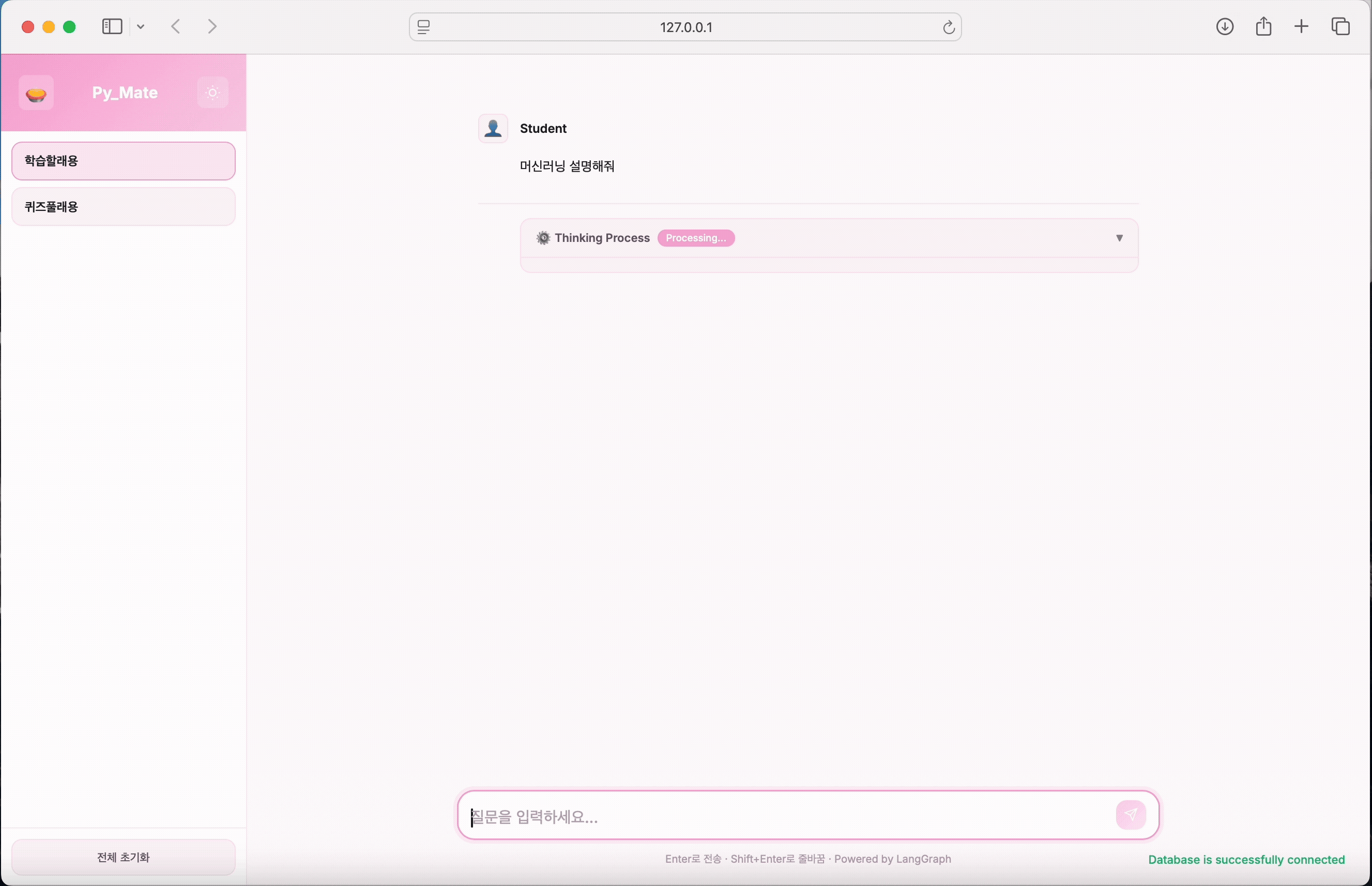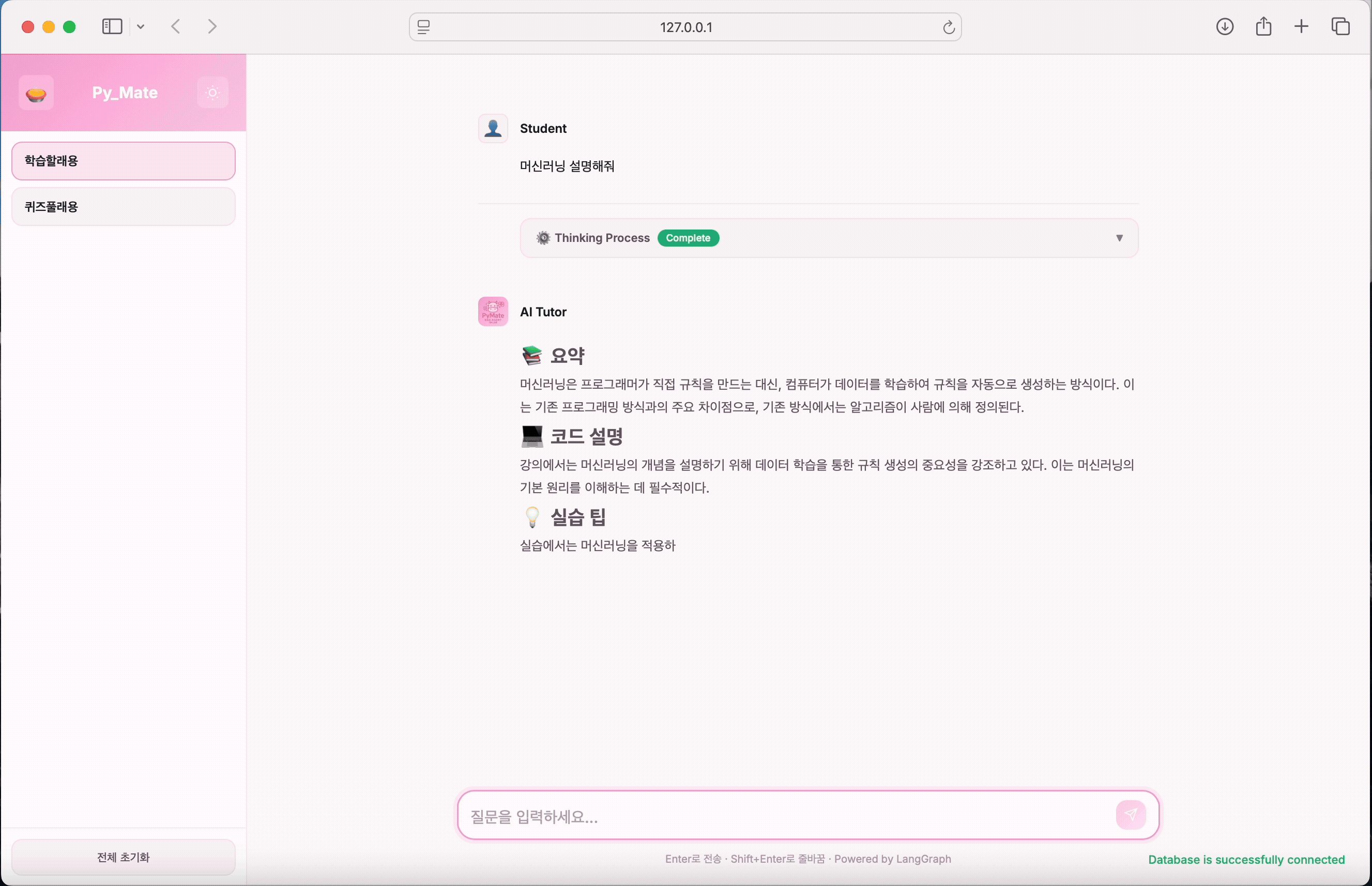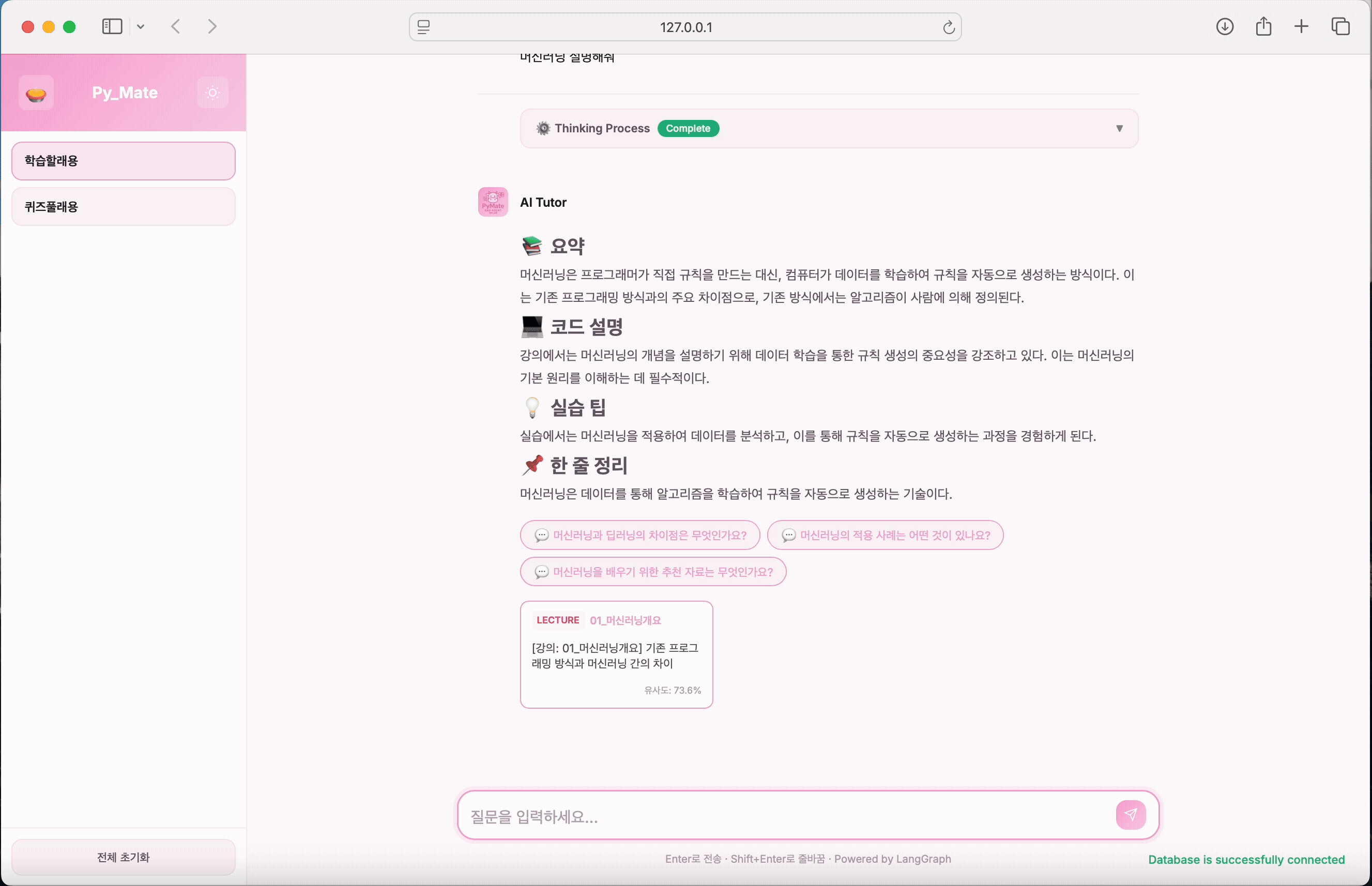
원래 메뉴가 학습할래용 하나였는데 퀴즈풀래용이 추가되었다.
기간이 짧다보니까 1차적으로 RAG 기반 AI Agent가 완성되어야한다가 가장 큰 목표였는데 나름 잘 마무리 되고 있을때 팀원 중 한분이 기능 추가 하고 싶다고 따로 개발을 해오셨다. 결국 우리의 PyMate는 더 풍부해졌고, 재밌는 요소까지 담을 수 있었다.
할일만 잘하는게 아니라 할일도 잘하고 능동적으로 찾아서 하는 팀원들의 모습들이 너무 매력있고 대단하고 함께 으쌰으쌰 할 수 있어서 많이 배울 수 있었다.
GitHub - SKNETWORKS-FAMILY-AICAMP/SKN21_3rd_4Team
Contribute to SKNETWORKS-FAMILY-AICAMP/SKN21_3rd_4Team development by creating an account on GitHub.
github.com
'AI > AI TECH' 카테고리의 다른 글
| [AWS] VPC - EC2 초기 설정 (1) | 2026.01.26 |
|---|---|
| [LLM] Finetuning 양자화와 PEFT (1) | 2026.01.10 |
| [RAG] Advanced RAG (0) | 2025.12.29 |
| [플레이데이터 SK네트웍스 Family AI 캠프 21기] 12월 1주차 회고 (0) | 2025.12.08 |
| [플레이데이터 SK네트웍스 Family AI 캠프 21기] 11월 4주차 회고 - 2차 단위프로젝트 (0) | 2025.12.01 |


