반응형
Row (행)
데이터프레임의 행 데이터를 구분하는 방법에는 index position(위치 기반) 과 index label(이름 기반) 존재한다.
import pandas as pd
df = pd.DataFrame({
'name': ['Tom', 'Jane', 'Steve', 'Lucy'],
'age': [28, 31, 24, 27],
'city': ['Seoul', 'Busan', 'Incheon', 'Daegu']
},
index=['a', 'b', 'c', 'd']) # index label 지정, 없으면 default 0,1,2,,, 설정됨.
df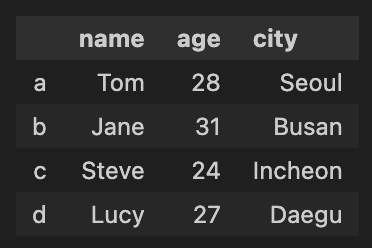
df의 index position은 [0,1,2,3]이고, 인덱스 이름은 ['a', 'b', 'c', 'd']이다.
| iloc | loc |
| index position | index label |
| [0:5] -> 끝 제외 -> [0,1,2,3,4] | [a:d] -> 끝 포함 -> [a,b,c,d] |
# 첫 번째 행 선택
position = df.iloc[0]
label = df.loc["a"]
print(position)
print(label)position과 label이 출력하는 데이터는 동일하다.
📌 그럼, 행을 추가할 때는 어떻게 되는가?
행 추가하는 방법은 2가지가 있는데 label을 추가하는 것과 concat으로 두가지의 df를 하나로 합치는것.
df.loc['e'] = ['Chris', 29, 'Gwangju']
new_row = pd.DataFrame({
'name': 'Chris',
'age': 29,
'city': 'Gwangju'
},
index=['e'])
df = pd.concat([df, new_row])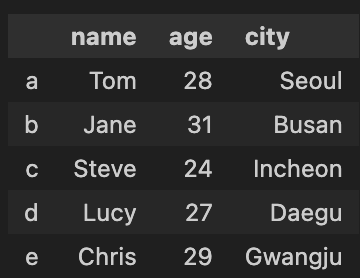
index label을 'e'로 지정해서 행 추가한 경우, index label을 지정하지 않고 새로운 df를 concat하게 되면❓
'e'가 아닌 default index label인 0부터 설정되게 된다. "0 Chris 29 Gwangju"
index label은 primary key 개념이 아니라 그냥 이름이므로 중복이 허용된다. Pandas가 "관계형 데이터베이스(RDB)"보다는 "label이 있는 Numpy 배열"에 더 가깝게 설계되었기 때문에 DB 느낌보다는 별명이라고 생각하면 된다.
-> 예를들어, 나중에 groupby할 때 label 기반 원하는 데이터의 결과를 얻기 쉽다.
Column (열)
열에도 column label과 index가 존재한다.
📌 column label로 데이터 얻어오는 방법 : [], dot
# 단일 열
df['name']
df.name
# 여러 열
df[['name', 'age']]📌 index로 데이터 얻어오는 방법 : iloc[row index position : column index position]
df.iloc[:, 0] # 첫 번째 열 (name)
df.iloc[:, 1:3] # 두 번째~세 번째 열 (age, city)
반응형
'AI > Python' 카테고리의 다른 글
| [Python] Web Crawling - 정적 웹 페이지 🆚 동적 웹 페이지 (0) | 2025.10.26 |
|---|---|
| [Python] Yield 키워드와 Generator 함수 (0) | 2025.10.13 |
| [Python] 파일 읽고 쓰기 with문 - ContextManager (0) | 2025.10.12 |
| [Python] 클래스의 던더 변수 및 메소드 (0) | 2025.10.04 |
| [Python] 클래스와 변수 + 접근지정자 getter, setter (0) | 2025.10.01 |